728x90
학습 내용
- 지도학습 알고리즘 중 분류 문제에서 사용되는 알고리즘에 대해 학습하고자 한다
의사결정나무
- 지도학습 알고리즘 (분류, 회귀)
- 직관적인 알고리즘 (이해 쉬움)
- 과대적합되기 쉬운 알고리즘 (트리 깊이 제한 필요)
- 정보이득(Infomation gain)이 최대가 되는 특성을 나누는 기준(불순도를 측정하는 기준)은 '지니'와 ’엔트로피’가 사용됨
- 데이터가 한 종류만 있다면 엔트로피/지니
- 불순도는 0에 가까움, 서로 다른 데이터의 비율이 비슷하면 1에 가까움
- 정보이득(Infomation gain)이 최대 (1-불순도)
# 의사결정나무
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(random_state=0)
model.fit(X_train, y_train)
pred = model.predict(X_test)
accuracy_score(y_test, pred)
DesicionTreeClassifier 하이퍼파라미터
• criterion (기본값 gini) : 불순도 지표 (또는 엔트로피 불순도 entropy)
• max_depth (기본값 None) : 최대 한도 깊이
• min_samples_split (기본값 2) : 자식 노드를 갖기 위한 최소한의 데이터 수
• min_samples_leaf (기본값 1) : 리프 노드가 되기 위한 최소 샘플 수
# 의사결정나무 하이퍼파라미터
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(
criterion = 'entropy',
max_depth = 7,
min_samples_split = 2,
min_samples_leaf=2,
random_state=0)
model.fit(X_train, y_train)
pred = model.predict(X_test)
accuracy_score(y_test, pred)의사결정나무 장점
- 범주와 연속형 수치를 모두 예측할 수 있다.
- 구조가 단순하여 해석이 용이하고, 유용한 입력 변수의 파악, 예측 변수 간의 상호작용, 비 선형성을 고려하여 수학적 가정이 불필요한 비모수적 모형이다.
- 시장조사, 광고조사, 의학연구, 품질관리 등 다양한 분야에서 활용되고 있다.
- 고객 타겟팅, 고객의 신용점수화, 캠페인에 대한 반응, 고객 행동 예측 등에 유용하다.
의사결정나무 단점
- 분류 기준값의 경계선 근방의 자료 값에 대해서는 오차가 클 수 있다.
- 로지스틱 회귀와 같이 각 예측 변수의 효과를 파악하기 어렵다.
- 새로운 자료에 대한 예측이 불안정할 수 있다. 이상치가 있을 경우 예측력이 떨어진다.
- 상위 노드로부터, 하위 노드로 트리구조를 형성하는 모든 단계마다 기준값의 선택이 중요하다.
랜덤포레스트
- 지도학습 알고리즘 (분류, 회귀)
- 의사결정나무의 앙상블
- 여러 개의 의사결정 트리로 구성
- 성능이 좋음 (과대적합 가능성 낮음)
- 부트스트랩 샘플링 (데이터셋 중복 허용)
- 최종 다수결 투표
- 앙상블
- 배깅 : 같은 알고리즘으로 여러 모델을 만들어 분류함 (랜덤포레스트)
- 부스팅 : 학습과 예측을 하면서 가중치 반영 (xgboost)
# 랜덤포레스트
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(random_state=0)
model.fit(X_train, y_train)
pred = model.predict(X_test)
accuracy_score(y_test, pred)
랜덤포레스트 하이퍼파라미터
- n_estimators (기본값 100) : 트리의 수
- criterion (기본값 gini) : 불순도 지표
- max_depth (기본값 None) : 최대 한도 깊이
- min_samples_split (기본값 2) : 자식 노드를 갖기 위한 최소한의 데이터 수
- min_samples_leaf (기본값 1) : 리프 노드가 되기 위한 최소 샘플 수
# 랜덤포레스트 하이퍼파라미터
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=500, max_depth=5, random_state=0)
model.fit(X_train, y_train)
pred = model.predict(X_test)
accuracy_score(y_test, pred)xgboost
- extreme Gradient Boosting (익스트림 그레이던트 부스팅)
- 부스팅(앙상블) 기반의 알고리증
- 트리 앙상블 중 성능이 좋은 알고리즘
- 캐글(글로벌 AI 경진대회) 뛰어난 성능을 보이면서 인기가 높아짐
# xgboost
from xgboost import XGBClassifier
model = XGBClassifier(random_state=0, use_label_encoder=False, eval_metric='logloss')
model.fit(X_train, y_train)
pred = model.predict(X_test)
accuracy_score(y_test, pred)xgboost 하이퍼 파라미터
- booster (기본값 gbtree) : 부스팅 알고리즘 (또는 dart, gblinear)
- objective (기본값 binary:logistic) : 이진분류 (다중분류: multi:softmax)
- max_depth (기본값 6) : 최대 한도 깊이
- learning_rate (기본값 0.1) : 학습률
- n_estimators (기본값 100) : 트리의 수
- subsample (기본값 1) : 훈련 샘플 개수의 비율
- colsample_bytree (기본값 1) : 특성 개수의 비율
- n_jobs (기본값 1) : 사용 코어 수 (-1: 모든 코어를 다 사용)
# xgboost 하이퍼파라미터
model = XGBClassifier(random_state=0, use_label_encoder=False, eval_metric='logloss',
booster = 'gbtree',
objective = 'binary:logistic',
max_depth = 5,
learning_rate = 0.05,
n_estimators = 500,
subsample = 1,
colsample_bytree = 1,
n_jobs = -1
# - booster(기본값 gbtree): 부스팅 알고리즘 (또는 dart, gblinear)
# - objective(기본값 binary:logistic): 이진분류 (다중분류: multi:softmax)
# - max_depth(기본값 6): 최대 한도 깊이
# - learning_rate(기본값 0.1): 학습률
# - n_estimators(기본값 100): 트리의 수
# - subsample(기본값 1): 훈련 샘플 개수의 비율
# - colsample_bytree(기본값 1): 특성 개수의 비율
# - n_jobs(기본값 1): 사용 코어 수 (-1: 모든 코어를 다 사용)
)
model.fit(X_train, y_train)
pred = model.predict(X_test)
accuracy_score(y_test, pred)
# 조기종료 : 더 이상 성능향상이 없을 때
model = XGBClassifier(random_state=0, use_label_encoder=False, eval_metric='logloss',
learning_rate = 0.05,
n_estimators = 500)
eval_set = [(X_test, y_test)]
model.fit(X_train, y_train, eval_set=eval_set, early_stopping_rounds=10)
pred = model.predict(X_test)
accuracy_score(y_test, pred)
교차검증
- Kfold : 일반적으로 사용되는 교차검증 방법
# KFold
from sklearn.model_selection import KFold
model = DecisionTreeClassifier(random_state=0)
kfold = KFold(n_splits=5)
for train_idx, test_idx in kfold.split(X):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(accuracy_score(y_test, pred))- StratifiedKfold : 불균형한 타겟 비율을 가진 데이터가 한쪽으로 치우치는 것을 방지
# Stratified Kfold
from sklearn.model_selection import StratifiedKFold
model = DecisionTreeClassifier(random_state=0)
kfold = StratifiedKFold(n_splits=5)
for train_idx, test_idx in kfold.split(X, y):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(accuracy_score(y_test, pred))사이킷런 교차검증
사이킷런 내부 API를 통해 fit(학습) - predict(예측) - evaluation(평가)
# 교차검증
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X, y, cv=3) # 데이터를 3개로 쪼갬
scores
# 평균 점수
scores.mean()
# 교차검증 Stratified Kfold
kfold = StratifiedKFold(n_splits=5)
scores = cross_val_score(model, X, y, cv=kfold)
scores
# 평균 점수
scores.mean()평가(분류)
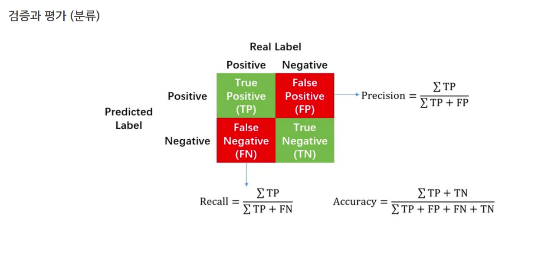
- 정확도 Accuracy: 실젯값과 예측값이 일치 비율
- 정밀도 precision: 양성이라고 예측한 값 중 실제 양성인 값 (암이라고 예측 한 값 중 실제 암일 확률)
- 재현율 recall: 실제 양성 값 중 양성으로 예측한 값 (실제 암인 값 중 예측도 암인 확률)
- F1: 정밀도와 재현율 조화 평균
- ROC-AUC
- ROC: 참 양성 비율(True Positive Rate)에 대한 거짓 양성 비율(False Positive Rate) 곡선
- AUC: ROC곡선 면적 아래 (완벽하게 분류되면 AUC가 1임)
- 정확도(accuracy) = $(TP + TN) / (TP + FP + FN + TN)$
- 정밀도(precision) = $TP / (TP + FP)$
- 재현율(recall) = $TP / (TP + FN)$
- F1 = 2 * (정밀도 * 재현율) / (정밀도 + 재현율)
Q. 정밀도(precision)와 재현율(recall)은 각각 어떤 상황에서 강조되어야 하는 지표인가요?
정밀도는 거짓 양성 비율(FPR)을 줄이는 것이 중요한 경우, 재현율은 거짓 음성 비율(FNR)을 줄이는 것이 중요한 경우 강조되어야 하는 지표입니다. 예를 들어, 이메일 스팸 필터링에서, 스팸 메일을 놓치면 큰 문제가 발생하지 않지만(FN), 일반 메일을 스팸으로 분류할 경우(FP), 중요한 메일을 놓칠 수 있습니다. 따라서, 스팸 메일을 정확하게 탐지하기 위해서는 정밀도가 더 중요한 지표가 될 수 있습니다. 의료 진단을 예로 들어보면, 실제 질병이 있는 환자를 놓치는 것(FN)은 큰 문제가 발생합니다. 따라서, 실제 양성인 환자를 탐지하기 위해서는 재현율이 더 중요한 지표가 될 수 있습니다.
출처
아이펠 스타터
728x90
'AIFFLE > STARTER' 카테고리의 다른 글
| [DL] 3. 딥러닝 구조와 모델 (0) | 2024.05.02 |
|---|---|
| [DL] 2. 텐서 표현과 연산 (0) | 2024.05.02 |
| [ML] 비지도학습 (0) | 2024.05.02 |
| [DL] 1. 딥러닝 (0) | 2024.05.01 |
| [ML] 지도학습(회귀) (0) | 2024.04.26 |
